

Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 204.24us 23.94us 626.00us 70.00us 68.70%
Req/Sec 75.56k 587.59 77.05k 73.92k 66.22%
Latency Distribution
50.00% 203.00us
90.00% 236.00us
99.00% 265.00us
99.99% 317.00us
12031718 requests in 10.00s, 1.64GB read
Requests/sec: 1203164.22
Transfer/sec: 167.52MB
This post will walk you through the performance tuning steps that I took to serve 1.2 million JSON "API" requests per second from a 4 vCPU AWS EC2 instance. For the purposes of this recreated quest, we will ignore most of the dead ends and dark alleyways that I had to struggle through on my solo expedition. Instead, we will mainly stick to the happy path, moving steadily from serving 224k req/s at the start, with the default configuration, to a mind-blowing 1.2M req/s by the time we reach the end.
Hitting 1M+ req/s wasn't actually my original intent. I started off working on a largely unrelated blog post, but I somehow found myself going down this optimization rabbit hole. The global pandemic gave me some extra time, so I decided to dive in head first. The table below lists the nine optimization categories that I will cover, and links to the corresponding flame graphs. It shows the percentage improvement for each optimization, and the cumulative throughput in requests per second. It is a pretty solid illustration of the power of compounding when doing optimization work.
The main takeaway from this post should be an appreciation for the tools and techniques that can help you to profile and improve the performance of your systems. Should you expect to get 5x performance gains from your webapp by cargo-culting these configuration changes? Probably not. Many of these specific optimizations won't really benefit you unless you are already serving more than 50k req/s to begin with. On the other hand, applying the profiling techniques to any application should give you a much better understanding of its overall behavior, and you just might find an unexpected bottleneck.
I considered breaking this post up across multiple entries, but decided to keep everything together for simplicity. Clicking the menu icon at the top right will open a table of contents so that you can easily jump to a specific section. For those who want to get their hands dirty and try it out, I have provided a CloudFormation template that sets up the entire benchmark environment for you.
# Basic Benchmark Setup
This is a basic overview of the benchmark setup on AWS. Please see the Full Benchmark Setup section if you are interested in more details. I used the Techempower JSON Serialization test as the reference benchmark for this experiment. For the implementation, I used a simple API server built with libreactor, an event-driven application framework written in C. This API server makes use of Linux primitives like epoll, send, and recv with minimal overhead. HTTP parsing is handled by picohttpparser, and libclo takes care of JSON encoding. It is pretty much as fast as you can get (pre io_uring anyway), and it is the perfect foundation for an optimization focused experiment.
- Server: 4 vCPU c5n.xlarge instance.
- Client: 16 vCPU c5n.4xlarge instance (the client becomes the bottleneck if I try to use a smaller instance size).
- Network: Server and client located in the same availability zone (use2-az2) in a cluster placement group.
- Operating System: Amazon Linux 2 (kernel 4.14).
-
Server: I ran the Techempower libreactor implementations (between round 18 and round 20) manually in a docker container:
docker run -d --rm --network host --init libreactor. - Client: I made a few modifications to wrk, the popular HTTP benchmarking tool, and nicknamed it twrk. twrk delivers more consistent results on short, low latency test runs. The standard version of wrk should yield similar numbers in terms of throughput, but twrk allows for improved p99 latencies, and adds support for displaying p99.99 latency.
# Benchmark Configuration
The benchmark was run three times and the highest and lowest results were discarded. twrk was run manually from the client using the same headers as the official benchmark and the following parameters:
- No pipelining.
- 256 connections.
- 16 threads (1 per vCPU), with each thread pinned to a vCPU.
- 2 second warmup before stats collection starts, then the test runs for 10s.
twrk -t 16 -c 256 -D 2 -d 10 --latency --pin-cpus "http://server.tfb:8080/json" -H 'Host: server.tfb' -H 'Accept: application/json,text/html;q=0.9,application/xhtml+xml;q=0.9,application/xml;q=0.8,*/*;q=0.7' -H 'Connection: keep-alive'
I want to take a moment to marvel at the advances in engineering and economies of scale that led to a world where I can rent a tiny slice of a (near) bare-metal server, on a low-latency, high performance network, and pay for it on a per second basis. Whatever your particular views on AWS may be, the infrastructure capabilities that they have made broadly available are nothing short of impressive. 15 years ago I couldn't even imagine taking on a project like this "just for fun".
# Ground Zero
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 1.14ms 58.95us 1.45ms 0.96ms 61.61%
Req/Sec 14.09k 123.75 14.46k 13.81k 66.35%
Latency Distribution
50.00% 1.14ms
90.00% 1.21ms
99.00% 1.26ms
99.99% 1.32ms
2243551 requests in 10.00s, 331.64MB read
Requests/sec: 224353.73
Transfer/sec: 33.16MB
At the start of our journey, the initial libreactor implementation is capable of serving 224k req/s. That's nothing to scoff at; most applications don't need anything near that kind of speed. The twrk output above shows our starting point.
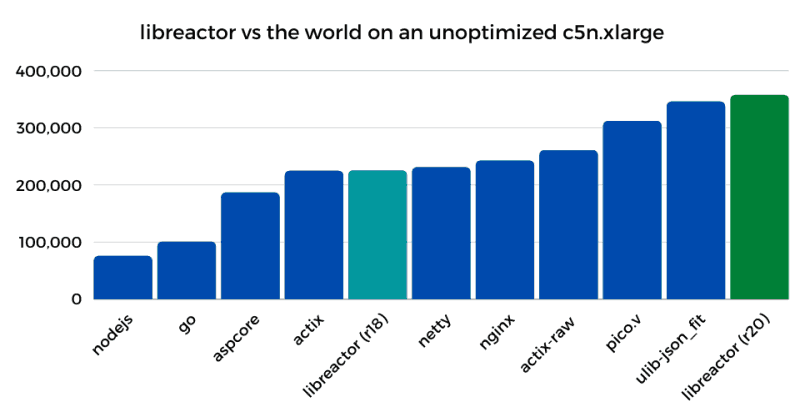
The bar chart below compares the throughput (req/s) of the initial libreactor implementation (round 18) vs the current implementations of a few popular servers/frameworks (round 20) running on a c5n.xlarge server in its default configuration.
Actix, NGINX, and Netty are well known, highly performant HTTP servers, and libreactor is right up there with them. Just looking at the bar chart you might think there really isn't much room for improvement, but of course you would be wrong. Understanding where you stand relative to the rest of the pack is useful, but that shouldn't stop you from trying to see what else can be improved.
# Flame Graphs
Flame Graphs provide a unique way to visualize CPU usage and identify your application's most frequently used code-paths. They are a powerful optimization tool, as they allow you to quickly identify and eliminate bottlenecks. You will see flame graphs throughout the document, serving as illustrated milestones of the progress being made, and the challenges to be conquered.
The initial flame graph gives us a snapshot of the inner workings of our application. I customized the flame graphs in this post so that the user-land functions are in blue, while kernel functions remain "flame" colored. Already we can quickly glean that most of the CPU time is spent in the kernel, sending/receiving messages over the network. This means that our application is already pretty efficient; it mostly gets out of the way while the kernel moves data.
The user-land code is split between parsing the incoming http request and dispatching a response. The tall, thin needle-looking stacks scattered throughout the graph represent interrupt related processing for incoming requests. These stacks are randomly spread out because interrupts can happen anywhere.

Clicking the image above will open the original SVG file that was generated by the Flamegraph tool. These SVGs are interactive. You can click a segment to drill down for a more detailed view, or you can search (Ctrl + F or click the link at the top right) for a function name. When you search, it highlights the relevant stack frames in purple, and shows the relative percentage that those frames represent. Searching the graph for ret_from_intr will give you an idea of the CPU time spent on interrupts. See the appendix for details on how the flame graphs were generated.
This thrilling quest for outrageous performance is for entertainment purposes (mostly). Don't try this at home... well fine, try it at home, but not at work, unless you really know what you are doing. Any C code that I have personally written should be considered a proof of concept at best. The last time I wrote C before relearning it for this project was 20 years ago. I know that libreactor is used in production by its creator, but I do not currently use any of this code in a production environment.
# 1. Application Optimizations
I started out with the libreactor code from round 18* of the Techempower benchmark series. I contributed my benchmark implementation changes directly to the Techempower repo, and opened issues on the libreactor repo for framework level changes. Those framework changes were then resolved in the libreactor 2.0 branch. The round 20 implementation contains all of the implementation level and framework level optimizations covered in this post.
# Implementation Optimizations
# vCPU Usage
As it turns out, the very first optimization that I found was dead simple, and I stumbled upon it without any sophisticated analysis. I ran htop on the server while the benchmark was running and noticed that the libreactor app was only running on 2 of the 4 available vCPUs.
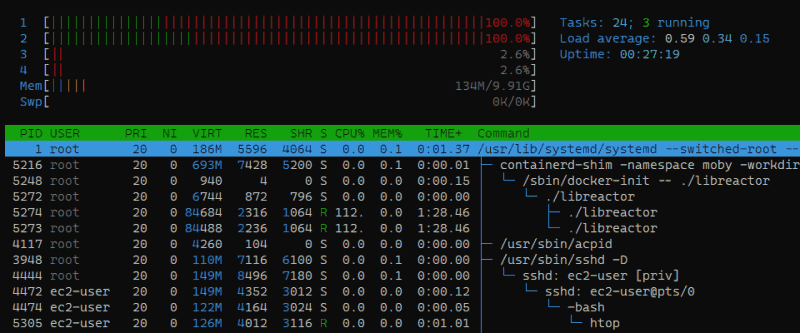
That's right, the libreactor implementation of the benchmark was basically fighting with one arm tied behind its back, so that was the very first thing I addressed and it improved throughput by over 25%! If you expected a bigger improvement you should keep in mind that (1) The "unused" logical cores were still handling some of the IRQ processing* and (2) These are hyper-threaded vCPUs which means that there are 2 physical cores which are presented as 4 logical cores. Using all 4 logical cores is definitely faster, but there is bound to be some resource contention, so you can't expect performance to double.
# GCC
The next thing that I noticed was that even though the app was being compiled with the -O3 GCC flag, no optimization flag was being applied when the framework itself was being built, so that was my next optimization.
Finally, when the 2.0 branch of libreactor was created, the -march-native GCC flag was added to the framework's Makefile, and I noticed that adding it to the app improved performance as well. I suspect this has to do with ensuring that the same set of options are used for all components when building with Link Time Optimizations.
# Framework Optimizations
# send/recv
libreactor 1.0 uses Linux's read and write functions for socket based communication. Using read/write when working sockets is equivalent to the more specialized recv and send functions, but using recv/send directly is still a little more efficient. Generally the difference is negligible, however when you move beyond 50k req/s it starts to add up. You can take a look at the GitHub issue that I created for more details, including before and after flame graphs. This issue was resolved in the libreactor 2.0 branch.
# Avoiding pthread Overhead
Along the same lines, even though Linux pthreads have very little overhead, if you really crank things up, the overhead becomes visible. I noticed that libreactor was creating a thread pool to facilitate asynchronous name resolution. This is useful if you are writing an HTTP client that is connecting to many different domains and you want to avoid blocking on DNS lookups. It is a lot less important when launching an HTTP server that only needs to resolve its own address before binding to a socket. Ordinarily this is something you wouldn't give a second thought since the thread pool is only created at startup and then never used again. However in this case there is still some thread management functionality in place and some corresponding overhead. Even under the extreme conditions of this test the overhead is only around 3%, but 3% is a lot for something that isn't being used.
If the server is built without link time optimization (-flto), the overhead shows up in flame graphs as __pthread_enable_asynccancel and __pthread_disable_asynccancel. The overhead isn't visible on the flame graphs in this post because these flame graphs are all generated from a -flto enabled build. You can check out the libreactor GitHub issue that I opened for more details, including a flame graph where __pthread_enable_asynccancel and __pthread_disable_asynccancel are visible. This issue was also resolved in the libreactor 2.0 branch.
# Adding It All Up
Here is a rough breakdown of all the application changes and their contributions to the performance gain. Bear in mind that these are not exact figures; they are just intended to give an idea of the relative impact.
- Run on all vCPUs: 25-27%
- Use gcc -O3 when building the framework: 5-10%
- Use march=native when building the app: 5-10%
- Use send/recv instead of write/read: 5-10%
- Avoid pthread overhead: 2-3%
The figures are inexact for a couple of reasons:
- The changes didn't all happen in the order outlined above, but for the purpose of putting together a coherent blog post I decided to group them.
- Optimizations are not just cumulative, they are also complementary. Each subsequent optimization may benefit from a bottleneck removed by the previous optimization, and as a result be even more effective.
As an example, the change to run libreactor on all 4 vCPUs increases throughput by just over 25% if it is the very first optimization, however if it were the absolute last of all the optimizations in this post, its contribution would be a 40+% increase, because those previously "idle" vCPUs are now able to contribute in a more efficient way.
I should also note that libreactor went through significant refactoring between version 1.0 and 2.0. That may have contributed to the improved performance as well, but I did not attempt to isolate the impact of those changes.
These changes bring our libreactor implementation almost fully in sync with the round 20 code. The one missing piece is enabling SO_ATTACH_REUSEPORT_CBPF, but that will get covered later on.
Altogether this gives us a performance boost of around 55%. Throughput moves from 224k req/s to 347k req/s.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 735.43us 99.55us 4.26ms 449.00us 62.05%
Req/Sec 21.80k 727.56 23.42k 20.32k 62.06%
Latency Distribution
50.00% 723.00us
90.00% 0.88ms
99.00% 0.94ms
99.99% 1.08ms
3470892 requests in 10.00s, 483.27MB read
Requests/sec: 347087.15
Transfer/sec: 48.33MB
# Flame Graph Analysis
The most obvious change compared to the initial flame graph is the reduction in width and height of the frames representing user-land code (in blue) courtesy of the -O3 gcc optimization flag being enabled. The switch from read/write to recv/send is also plainly visible. Finally, the overall increase in throughput brings an increase in the frequency of interrupts as we now see a much greater density of ret_from_intr "needles" on the graph. A search for ret_from_intr shows it moved from 15% of the initial graph to 27% of the current one.

# 2. Speculative Execution Mitigations
The next optimization is both significant and controversial: disabling speculative execution mitigations in the Linux kernel. Now, before you run and get your torches and pitchforks, first take a deep breath and slowly count to ten. Performance is the name of the game in this experiment, and as it turns out these mitigations have a big performance impact when you are trying to make millions of syscalls per second.
Performance aside, while these mitigations are sensible defaults that should just be left alone in most cases, I think there is still room for healthy discussion around turning them off in scenarios where the benefits outweigh the risks. Let's suppose, on the one hand, that you have a multi-user system that relies solely on Linux user permissions and namespaces to establish security boundaries. You should probably leave the mitigations enabled for that system. On the other hand, suppose you are running an API server all by itself on a single purpose EC2 instance. Let's also assume that it doesn't run untrusted code, and that the instance uses Nitro Enclaves to protect extra sensitive information. If the instance is the security boundary and the Nitro Enclave provides defense in depth, then does that put mitigations=off back on the table?
AWS seems to be pretty confident in the "instances as the security boundary" approach. Their standard response to Spectre/Meltdown class vulnerabilities is:
AWS has designed and implemented its infrastructure with protections against these types of attacks.
No customer’s instance can read the memory of another customer’s instance, nor can any instance read AWS hypervisor memory.
We suggest using the stronger security and isolation properties of instances to separate any untrusted workloads.
Of course they also include a blanket disclaimer as well:
As a general security best practice, we recommend that customers patch their operating systems or software as relevant patches become available.
But my assumption is that they need to include that so people don't just turn the mitigations off without properly evaluating their individual use cases.
Speculative execution is not just a single attack, it is a class of vulnerabilities, with new attacks still yet to be discovered. It seems to me that if you start with the assumption that these mitigations are disabled, and model your approach to use the instance/VM as the security boundary, you will presumably have a better long term security posture. Those that have the time and resources to take such an approach will likely be ahead of the game. I am genuinely interested in hearing the opinions of more security experts on this. If this is your area of expertise, feel free to leave a comment on Hacker News or Reddit. You can also contact me directly if you prefer.
Anyway, for the purposes of this experiment, performance=good, mitigations=off; so let's get to the details of which mitigations I actually disabled. Here is the list of kernel parameters that I used:
nospectre_v1 nospectre_v2 pti=off mds=off tsx_async_abort=off
# Disabled Mitigations
# Spectre v1 + SWAPGS
The mitigations for the original v1 bounds check bypasses can’t be disabled, however I still disabled the SWAPGS mitigations using the nospectre_v1 kernel parameter. In my testing, disabling the SWAPGS barriers resulted in a small (1-2%) performance increase.
# Spectre v2
I disabled the Spectre v2 mitigations using the nospectre_v2 kernel parameter. The performance impact was significant, around 15-20%.
# Spectre v3/Meltdown
I disabled KPTI using the pti=off kernel parameter. This resulted in a performance increase of around 6%.
# MDS/Zombieload and TSX Asynchronous Abort
I disabled MDS using mds=off and TAA using tsx_async_abort=off. The same mitigation is used for both vulnerabilities. Performance improved around 10% when both were disabled.
# Mitigations left unchanged
# L1TF/Foreshadow
PTE inversion is permanently enabled. l1tf=flush is the default parameter setting but it is not relevant since we are not doing nested virtualization. l1tf=off has no effect so I left the default as is.
# iTLB multihit
iTLB multihit is only relevant if you are running KVM, so it doesn't apply since AWS doesn't support running KVM on an EC2 instance.
# Speculative Store Bypass
There doesn’t seem to be a mitigation available in the kernel for this vulnerability; instead, it is addressed by an Intel microcode update. According to AWS their underlying infrastructure is not affected, and there was an update that referenced this CVE. The kernel still lists spec_store_bypass as vulnerable so this may be a case of the OS not having access to check the microcode.
# SRBDS
The CPU used by the c5 family is not affected by this vulnerability.
Disabling these mitigations gives us a performance boost of around 28%. Throughput moves from 347k req/s to 446k req/s.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 570.37us 49.60us 0.88ms 398.00us 66.72%
Req/Sec 28.05k 546.57 29.52k 26.97k 62.63%
Latency Distribution
50.00% 562.00us
90.00% 642.00us
99.00% 693.00us
99.99% 773.00us
4466617 requests in 10.00s, 621.92MB read
Requests/sec: 446658.48
Transfer/sec: 62.19MB
# Flame Graph Analysis
Even though the performance boost was significant, the changes to the flame graph are pretty small since these mitigations are largely invisible to profiling. Nevertheless, if you compare the search results for __entry_trampoline_start and __indirect_thunk_start in the previous flame graph and the current one, you will see that they are now either completely gone or significantly reduced.

# 3. Syscall Auditing/Blocking
The overhead associated with the default syscall auditing/blocking done by Linux/Docker is imperceptible for most workloads; but when you are trying to do millions of syscalls per second, the story changes and those functions start to show up on your flame graph. If you search the previous flame graph for "audit|seccomp" you will see what I mean.
# Disable Syscall Auditing
The Linux kernel audit subsystem provides a mechanism for collecting and logging security events like access to sensitive files or system calls. It can help you troubleshoot unexpected behavior or collect forensic evidence in the event of a security breach. The audit subsystem is on by default on Amazon Linux 2, but it is not configured to log syscalls.
Even though syscall logging is disabled by default, the audit subsystem still adds a tiny amount of overhead to each syscall. The good news is that this can be overridden with a relatively simple rule: auditctl -a never,task, so I created a custom config file that does just that. If you are actually using the audit subsystem to log syscalls, this is a non-starter, but I suspect that most users aren't. According to this Bugzilla issue Fedora uses the same rule by default.
# Disable Syscall Blocking
By default, docker enforces limits on the processes running in a container using namespaces, cgroups, and a restricted set of linux capabilities. In addition to this, a seccomp filter is used to constrain the list of syscalls that an application can make.
Most containerized applications can run under these restrictions with no issue, but there is a small amount of overhead involved in policing the syscalls. Your first instinct may be to run docker with the --privileged option, and while that would work, it would also give the container way more linux capabilities than it needs. Instead, we can use the --security-opt option, so that only the seccomp filter gets disabled. Our new docker run command looks like this:
docker run -d --rm --network host --security-opt seccomp=unconfined --init libreactor
Combined, this gives us a performance boost of around 11%. Throughput moves from 446k req/s to 495k req/s.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 514.02us 39.05us 1.65ms 134.00us 67.34%
Req/Sec 31.09k 433.78 32.27k 30.01k 65.97%
Latency Distribution
50.00% 513.00us
90.00% 565.00us
99.00% 604.00us
99.99% 696.00us
4950091 requests in 10.00s, 689.23MB read
Requests/sec: 495005.93
Transfer/sec: 68.92MB
# Flame Graph Analysis
This removes the syscall trace/exit overhead completely. With both these changes applied, syscall_trace_enter and syscall_slow_exit_work disappear from the flame graph.

One additional note, even though the docker documentation says the apparmor has a default profile as well, it doesn't seem to be enabled on Amazon Linux 2. There was no noticeable change in performance (or the flame graph) when I used the --security-opt apparmor=unconfined option.
# 4. Disabling iptables/netfilter
iptables/netfilter* is the core component used by traditional Linux firewalls to control network access. It is also an extremely powerful and flexible networking tool that many other applications depend on for things like Network Address Translation (NAT). Under the extreme load of this test, the overhead of iptables is significant, so it is the next target in our quest. In the previous flame graph the iptables overhead shows up on both the send and receive side as the nf_hook_slow kernel function; a quick search of the flame graph shows that it accounts for almost 18% of the total frames.
Disabling iptables is not quite as controversial as it may have once been from a security perspective. With the advent of cloud computing, the firewall strategy for many deployments has shifted from iptables to cloud-specific primitives like AWS Security Groups. Nevertheless many of those same deployments are still implicitly using iptables for NAT, especially in environments where Docker containers are widely used. It is not enough to simply turn off iptables, you must also go through and update/replace any applications that depend on it.
For the purposes of this test we are going to disable iptables support in the kernel and in the docker daemon. We can get away with this because we are running a single container directly connected to the host network, so there is no need for network address translation. The main thing to keep in mind is that once you have disabled Docker's iptables support you will need to use the --network host option with any command that interacts with the network, including docker build.
I intentionally chose to disable the kernel module at startup rather than blacklist it, which means that re-enabling it is as simple as running the iptables command to add a new rule. This makes things simpler if you need to quickly add a dynamic rule to block a newly discovered vulnerability, but it is also a double-edged sword as it makes it easy for it to be accidentally re-enabled by a third party script or program. A more robust strategy would be to switch to nftables, the successor to iptables that promises better performance and extensibility. I did some limited testing with nftables and found that by default there is no negative performance impact from having the kernel module loaded if the rules table is empty, whereas with iptables, the performance impact is significant even without any rules.
The downside for nftables is that support from Linux distros is relatively new, and support from third party tools is very much a work in progress. Docker is a perfect example of lack of support on the tools side. As far as distros are concerned, Debian 10, Fedora 32, and RHEL 8 have all switched to nftables as the default backend. They use the iptables-nft layer to act as a (mostly) compatible user-land replacement for iptables. Ubuntu developers have tried to make the switch for both the 20.04 and 20.10 releases, but it seems they ran into compatibility issues both times. Amazon Linux 2 still uses iptables by default. If your distro supports nftables it should be possible to have your cake and eat it too, by leaving the kernel module in place and simply making changes to your docker config. Hopefully one day Docker will offer native nftables support with the minimal set of rules required to balance performance and functionality.
Disabling iptables gives us a performance boost of around 22%. Throughput moves from 495k req/s to 603k req/s.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 420.68us 43.25us 791.00us 224.00us 63.70%
Req/Sec 37.88k 687.33 39.54k 36.35k 62.94%
Latency Distribution
50.00% 419.00us
90.00% 479.00us
99.00% 517.00us
99.99% 575.00us
6031161 requests in 10.00s, 839.76MB read
Requests/sec: 603112.18
Transfer/sec: 83.98MB
# Flame Graph Analysis
These changes remove the iptables overhead completely. nf_hook_slow is nowhere to be found in the flame graph.

# 5. Perfect Locality
Linux is a fantastic multi-purpose OS kernel that performs well under a wide variety of use cases. By default, the kernel tries its best to allocate resources as evenly as possible by automatically distributing load across multiple network queues, processes, and CPUs. This works really well most of the time, but when you want to move the needle from good performance to extreme performance, you have to exert tighter control on how things are done.
One technique that has emerged with the advent of multi-queue/CPU servers, is to essentially create distinct silos (similar to database shards) where each network queue is paired with a CPU, so that each pairing operates as independently from the others as possible. Both the OS and the application must be configured to ensure that once a network packet arrives on any given queue, all further processing is handled by the same vCPU/queue silo for both incoming and outgoing data. This focus on packet/data locality improves efficiency by maintaining CPU cache warmth, reducing context/mode switching, minimizing cross CPU communication, and eliminating lock contention.
# CPU Pinning
The first step towards achieving perfect locality is to ensure that a separate libreactor server process is created for, and pinned to, each of the available vCPUs on the instance. In our case this is handled by fork_workers(). Technically we have been using CPU pinning all along, but I wanted to highlight it here because of its importance in establishing the vCPU/queue silo.
# Receive Side Scaling (RSS)
The next step is to establish fixed pairings between network queues and vCPUs for incoming data (outgoing has to be handled separately). Receive Side Scaling is a hardware assisted mechanism for distributing network packets across multiple receive queues in a consistent manner. The AWS ENA driver supports RSS and it is enabled by default. A hash function (Toeplitz) is used to transform a fixed hash key (auto-generated at start up) and the src/dst/ip/port of the connection into a hashed value, then the 7 least significant bits of that hash are combined with the RSS indirection table to determine which receive queue a packet will be written to. This system ensures that incoming data from a given connection is always sent to the same queue. On the c5n.xlarge the default RSS indirection table spreads connections/data across the four available receive queues which is exactly what we need so we leave it unchanged.
Once the NIC writes a packet to the area of RAM reserved for the receive queue, the OS needs to be notified that there is data waiting to be processed; this event is known as a hardware interrupt. Each network queue is assigned an IRQ number which is essentially the dedicated hardware interrupt channel for that queue. To determine which CPU will handle an interrupt, each IRQ number is mapped to a CPU based on the value of /proc/irq/$IRQ/smp_affinity_list. By default, the irqbalance service updates the smp_affinity_list values to dynamically distribute the load. In order to maintain our silos we need to disable irqbalance and manually set the smp_affinity_list values so that queue 0 -> CPU 0, queue 1 -> CPU 1, etc.
systemctl stop irqbalance.service
export IRQS=($(grep eth0 /proc/interrupts | awk '{print $1}' | tr -d :))
for i in ${!IRQS[@]}; do echo $i > /proc/irq/${IRQS[i]}/smp_affinity_list; done;
Hardware interrupts and software interrupts (softirq) are automatically handled on the same CPU, so the silo is maintained for softirqs as well. This is important since the hardware interrupt handlers are extremely minimal and all the real work for processing the incoming packet is done by the softirq handler. Once softirq processing is complete, the data is ready to be passed on to the application by way of a listening socket.
The libreactor implementation uses the SO_REUSEPORT socket option to allow multiple server processes to listen for connections on the same port. This is a great option for distributing connections across multiple processes. By default it uses a simple hash function which is also based on the src/dst/ip/port, but unrelated to the one used for RSS. Unfortunately, since this distribution is random it breaks our siloed approach. An incoming packet might get mapped to CPU 2 for softirq processing and then get passed to the application process listening on CPU 0. Thankfully, as of kernel 4.6 we now have the option to load balance these connections in a more controlled way. The SO_ATTACH_REUSEPORT_CBPF socket option allows us to specify our own custom BPF* program that can be used to determine how connections are distributed. Let's say, for example, we have four server processes with sockets listening on the same port; the following BPF program will use the ID of the CPU that handled softirq processing for the packet to decide which of the four listening sockets/processes should receive the incoming connection.
{{BPF_LD | BPF_W | BPF_ABS, 0, 0, SKF_AD_OFF + SKF_AD_CPU}, {BPF_RET | BPF_A, 0, 0, 0}}
So, for example, if softirq processing was handled by CPU 0, then data for that connection is routed to socket 0. Let me quickly clarify something that was not immediately clear to me when I first tried using the SO_ATTACH_REUSEPORT_CBPF option. Socket 0 is not necessarily the socket attached to the process that is running on CPU 0, it is actually referring to the first socket that started listening on the ip/port combo for the SO_REUSEPORT group.
At first I didn't give much thought to this since I believed that I was starting the server processes (and opening sockets) in the same order that I was pinning them to their respective CPUs. I was just using a simple for loop to fork() a new worker process, pin it to a CPU, and start up the libreactor server. However, if you call fork() in a for loop like that, the order of the new process/socket creation is non-deterministic, which throws off the mapping between sockets and CPUs. Long story short, when using SO_ATTACH_REUSEPORT_CBPF you need to be extra careful about the order in which sockets are created. See the GitHub commit where I fixed the issue for more details.
# XPS: Transmit Packet Steering
Transmit Packet Steering essentially does for outgoing packets, what RSS does for incoming packets; it allows us to maintain our silo by ensuring that when our application is ready to send a response, the same vCPU/queue pairing is used. This is done by setting the value of /sys/class/net/eth0/queues/tx- (where n is the ID of the queue) to a hex bitmap that contains the corresponding CPU.
export TXQUEUES=($(ls -1qdv /sys/class/net/eth0/queues/tx-*))
for i in ${!TXQUEUES[@]}; do printf '%x' $((2**i)) > ${TXQUEUES[i]}/xps_cpus; done;
With these changes in place we have achieved perfect locality and a significant performance boost of approximately 38%. Throughput moves from 603k req/s to 834k req/s.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 301.65us 23.43us 692.00us 115.00us 68.96%
Req/Sec 52.41k 640.10 54.25k 50.52k 68.75%
Latency Distribution
50.00% 301.00us
90.00% 332.00us
99.00% 361.00us
99.99% 407.00us
8343567 requests in 10.00s, 1.13GB read
Requests/sec: 834350.86
Transfer/sec: 116.17MB
# Flame Graph Analysis
The changes in this flame graph are interesting. Compared to the previous flame graph the user-land block (in blue) is noticeably wider. It has moved from about 12% to 17% of the flame graph. Flame graph based profiling is not an exact science, and fluctuations of 1-2% across captures are to be expected, but this was a consistent change. At first I thought it might just be an uneven distribution of interrupts that was throwing things off, but further analysis showed that it was just a correlation. More CPU time spent in user-land means more interrupts will happen in user-land.
My theory is that the perfect locality changes allowed the kernel code to get its job done more efficiently. A greater number of packets are now being processed using even less CPU time. It is not that the user-land code has gotten slower, the kernel code has just gotten much faster. The recv stack in particular (represented by SYSC_recvfrom) goes from 17% down to 13% of the flame graph. This checks out because now that we have perfect locality, recv is always happening on the same CPU that handled the interrupt, which really speeds things up.

The benefits of the perfect locality approach are clear, but it is not wholly without limitations; the biggest strength is also the most notable weakness. Let's say, for example, you are only servicing a small number of connections, and that the distribution of those connections sends a disproportionate amount of load to CPU/queue 0. No other CPU will be able to handle IRQ processing, no other process will be assigned some of queue 0's connections, and no other queue will be used for outgoing transmissions. It's every vCPU/queue silo for themselves.
Also be aware that you need to be very careful about doing things like running on a limited number of CPUs using taskset or Docker's --cpuset-cpus option. It will work fine with the current BPF program if you use a contiguous range of CPUs, but if you try to get fancy you may need to write a more specific program. Depending on your architecture and your workload these limitations may be non-issues, but you should still be fully aware of them, as architectures and workloads can change over time.
Even with those caveats I think SO_ATTACH_REUSEPORT_CBPF is a powerful optimization when used effectively, and I hope to see more mainstream servers and frameworks taking advantage of it as an optional feature. I think part of the reason it has flown under the radar for so long is because it is hard to find good practical examples of how to use it. Hopefully this post can serve as a "realish-world" example of using it to achieve improved packet locality. I have seen discussions on the NGINX mailing list about adding SO_ATTACH_REUSEPORT_CBPF support, so it may become much more mainstream in the not too distant future. Like the libreactor implementation used in this benchmark, NGINX also has a process-per-core architecture and supports CPU pinning), so adding SO_ATTACH_REUSEPORT_CBPF support is potentially a big win if the OS is tuned to match.
# 6. Interrupt Optimizations
# Interrupt Moderation
When a data packet arrives over the network, the network card signals the operating system to let it know that there is incoming data to be processed. It does this using a hardware interrupt, and as the name indicates, it interrupts whatever else the OS was doing. This is done so that the network card's data buffers don't overflow and cause data to be lost. However when thousands of packets are coming in every second, this constant interruption causes a lot of overhead.
To mitigate this, modern network cards support interrupt moderation/coalescing. They can be configured to delay interrupts for a short period of time, and then raise a single interrupt for all the packets that arrived in that period. More advanced drivers like the AWS ENA driver support adaptive moderation which takes advantage of the kernel's dynamic interrupt moderation algorithm to adjust the interrupt delays dynamically. If network traffic is light, interrupt delays are reduced to zero and interrupts are triggered as soon as a packet is received, guaranteeing the lowest possible latency. As network traffic increases, the interrupt delay is increased to avoid overwhelming the system's resources; this increases throughput while keeping latency consistent.
The ENA driver supports fixed interrupt delay values (in microseconds) for incoming and outgoing data (tx-usecs, rx-usecs), and dynamic interrupt moderation for incoming data only (adaptive-rx on/off). By default, adaptive-rx is off, rx-usecs is 0 and tx-usecs is 64. In my testing I found setting adaptive-rx on and tx-usecs 256 to give the best balance of throughput and low latency across a range of workloads.
For our benchmark workload, turning on adaptive-rx improves throughput from 834k req/s to 955k req/s, a 14% increase. Turning on adaptive-rx is one of the few configuration changes in this post that have a lot of potential upside and very little downside for any one handling more than 10k req/s. As with anything though, be sure to test any changes with your workload to ensure that there are no unexpected side effects.
# Busy Polling
Busy polling is a relatively obscure (and not very well documented) networking feature that has existed since 2013 (kernel 3.11). It is designed for use cases where low latency is of the utmost importance. By default, it works by allowing a blocked socket to trigger polling for incoming data at the expense of additional CPU cycles and power usage. The feature can be enabled in a few different ways:
The
net.core.busy_readsysctl can be used to set the default value for busy polling when using recv/read, but only for blocking reads. This doesn't help us since we are doing non-blocking reads.The value of
net.core.busy_readcan be overridden on a per-socket basis using the SO_BUSY_POLL socket option, but again it doesn't apply to non-blocking reads.The
net.core.busy_pollsysctl is the third option for controlling this feature and it is the option that I used. The documentation implies that the setting is only relevant forpollandselect(notepollwhich libreactor uses) and explicitly states that only sockets with SO_BUSY_POLL set will be busy polled. It is possible that both those statements were true in the past, but neither is still true today. Busy polling support was added to epoll in 2017 (kernel 4.12) and based on the code and my testing, setting SO_BUSY_POLL on the socket is not a requirement.
When used with epoll, busy polling no longer works at the individual socket level but is instead triggered by epoll_wait. If busy polling is turned on and there are no events available when epoll_wait is called, then the NAPI subsystem harvests any unprocessed packets from the network card's receive queue, and runs them through softirq processing. In an ideal scenario those processed packets will then end up on the same sockets that the epoll instance was monitoring, and cause epoll to return with available events. All this can happen without any hardware interrupts or context switches.
The biggest downside of busy polling is the additional power and CPU usage that comes from polling for new data in a tight loop. The recommended value for net.core.busy_poll is between 50μs and 100μs, however in my testing I determined that I can still get all the benefits of busy polling (with almost none of the downside) with a value as low as 1μs. With net.core.busy_poll=50 the additional CPU usage of running the benchmark with just 8 connections is more than 45%, whereas with net.core.busy_poll=1 the additional CPU usage is only 1-2%.
It is important to highlight the extent to which interrupt moderation, busy_polling and SO_ATTACH_REUSEPORT_CBPF work together in a virtuous cycle. Take away any one of the three and you will see a much less pronounced effect in terms of throughput, latency, and the resulting flame graph. Without interrupt moderation, busy polling would hardly ever get a chance to run, and without SO_ATTACH_REUSEPORT_CBPF (and the other data locality settings) busy polling has very little effect. Note that the git commit message for adding busy polling to epoll specifically mentions using SO_ATTACH_REUSEPORT_CBPF in combination with busy polling for improved efficiency. This paper from netdev 2.1 Montreal 2017 goes into even more detail.
With interrupt coalescing and busy polling combined we get a performance boost of approximately 28%. Throughput moves from 834k req/s to 1.06M req/s, while p99 latency drops from 361μs to 292μs.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 233.13us 24.41us 636.00us 73.00us 70.59%
Req/Sec 66.96k 675.18 68.80k 64.95k 68.37%
Latency Distribution
50.00% 233.00us
90.00% 263.00us
99.00% 292.00us
99.99% 348.00us
10660410 requests in 10.00s, 1.45GB read
Requests/sec: 1066034.60
Transfer/sec: 148.43MB
# Flame Graph Analysis
The change to this flame graph is pretty dramatic compared to the previous one, but it is mostly just a difference of where the irq handling is being done. With interrupt coalescing and busy polling working together, softirq processing is happening proactively instead of being interrupt driven.

If you search the respective flame graphs for ena_io_poll, ret_from_intr, and napi_busy_loop you will see the overall proportion of softirq processing (as indicated by ena_io_poll) remains roughly the same, but the amount that is interrupt driven (all the thin spiky towers) drops from 25% to just over 6%, and the amount that is busy_poll driven jumps to almost 22%.
| Before | After | |
|---|---|---|
| ena_io_poll | 29.6% | 30.2% |
| ret_from_intr | 24.6% | 6.3% |
| napi_busy_loop | 0.0% | 21.9% |
You can see the difference even more plainly when looking at the detailed interrupt statistics generated by dstat:
dstat -y -i -I 27,28,29,30 --net-packets
# Before
---system-- -------interrupts------ -pkt/total-
int csw | 27 28 29 30 |#recv #send
183k 6063 | 47k 48k 49k 37k| 834k 834k
183k 6084 | 48k 48k 48k 37k| 833k 833k
183k 6101 | 47k 49k 48k 37k| 834k 834k
# After
---system-- -------interrupts------ -pkt/total-
int csw | 27 28 29 30 |#recv #send
16k 967 |3843 3848 3849 3830 |1061k 1061k
16k 953 |3842 3847 3851 3826 |1061k 1061k
16k 999 |3842 3852 3852 3827 |1061k 1061k
The total number of hardware interrupts per second drops dramatically from 183k to 16k. Also note that the total number of context switches drops from over 6000 to less than 1000, an impressively low number given that we are now handling over 1 million requests per second.
# 7. The Case of the Nosy Neighbor
Crossing the 1M req/s mark was a major milestone, I popped some virtual champagne via text messages and did a little dance. Nevertheless, I still felt like there were more gains to be had, and to be perfectly honest I had become a little optimization obsessed. At this point I was basically going through the flame graph with a magnifying glass trying to find anything that could be eliminated. I started with the _raw_spin_lock function at the top of the sendto syscall stack, but I ran into a number of dead ends trying to solve that one. Frustrated, I moved on, but as you will read in the next section, I eventually picked it up again.
Turning away from _raw_spin_lock, I set my sights on dev_queue_xmit_nit as the next target since it weighs in at 3.5% of the flame graph at this point. Looking at the source code dev_queue_xmit_nit should only be called if !list_empty(&ptype_all) || !list_empty(&dev->ptype_all) which roughly translates to "someone is listening in and getting a copy of every outgoing packet". A similar check happens for incoming packets as well inside __netif_receive_skb_core. If you search the flame graph for dev_queue_xmit_nit|packet_rcv, you will see packet_rcv in the incoming softirq stacks as well, and that the matched total is now 4.5%.
It would be perfectly reasonable to expect this overhead if I were running a program that does low level packet capture (e.g. tcpdump), but I wasn't. The fact that packet_rcv was being called meant that someone, somewhere had opened up a raw socket using AF_PACKET, and it was slowing things down. Thankfully I was able to eventually track down the culprit using ss. At first I tried ss --raw but it turns out that option only applies to AF_INET/SOCK_RAW sockets, but we are looking for an AF_PACKET/SOCK_RAW socket (don't ask, I didn't really dig into it). The following command finds the AF_PACKET raw socket and also reveals the name of the listening process: sudo ss --packet --processes. This unmasks our (performance) killer: (("dhclient",pid=3191,fd=5)). It was the DHCP client, in the library, with the raw socket.
Of course finding the culprit is only half the battle, resolving the issue is another story. The first thing I wondered was why the DHCP client needs to be listening on a raw socket in the first place. The answer that I found in the ISC knowledge base is below. Technically it is speaking from the perspective of the server, but I am sure the same logic applies for the client:
[the socket] Transmits directed unicasts (w/out ARP), and special RFC 2131 complying all-ones limited broadcasts. These are needed in clients' initial configuration stage (when the client does not yet have an address configured).
This makes sense, the DHCP client needs to be able to send and receive messages before the instance has been issued an IP address. The same KB article also mentions that a standard UDP socket is used to transmit routed unicasts for DHCP renewals. I was hoping that there was some way to get dhclient to close the raw socket after acquiring the initial address and just use the UDP socket for renewals, but that doesn't seem to be an option.
It should be noted that these packets never actually reach the dhclient, as there is likely a BPF filter in place on the socket that drops non-DHCP packets before they ever leave the kernel. Nevertheless, there is still overhead from the actions taken within the kernel, and we simply can't have that.
According to the docs, once AWS assigns a primary private IP address to an instance, it is associated with that instance for its lifetime, even across reboots and extended stops. Since DHCP renewals aren't critical for preventing the IP from being reassigned, I chose to disable dhclient after boot. In addition to stopping dhclient, it is also necessary to update the lifetime of the private address at the network device level (eth0) using ip address. By default the lifetime is 1 hour (and IPv4 renewals happen every 30 mins), so I manually set the lifetime to "forever".
sudo dhclient -x -pf /var/run/dhclient-eth0.pid
sudo ip addr change $( ip -4 addr show dev eth0 | grep 'inet' | awk '{ print $2 " brd " $4 " scope global"}') dev eth0 valid_lft forever preferred_lft forever
Disabling dhclient gives us a performance boost of just under 6%. Throughput moves from 1.06M req/s to 1.12M req/s.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 219.38us 26.49us 598.00us 56.00us 68.29%
Req/Sec 70.84k 535.35 72.42k 69.38k 67.55%
Latency Distribution
50.00% 218.00us
90.00% 254.00us
99.00% 285.00us
99.99% 341.00us
11279049 requests in 10.00s, 1.53GB read
Requests/sec: 1127894.86
Transfer/sec: 157.04MB
# Flame Graph Analysis
The dev_queue_xmit_nit and packet_rcv functions have been fully removed. Our nosy neighbor has been evicted.

NOTE: I want to make it absolutely clear that I have not tested this configuration on production workloads or for an extended period of time. There may be unanticipated side effects from disabling dhclient like this. This is simply a quick workaround; if anyone knows of a cleaner way to get dhclient to not listen on a raw socket, I would love to hear about it: Hacker News | Reddit | Direct.
# 8. The Battle Against the Spin Lock
I spent a considerable amount of time trying to subdue the sizable _raw_spin_lock frame at the top of the sendto stack (see previous flame graph). The kernel uses a few spin locks to manage the egress of network packets flowing through (or around) qdiscs, and out to the network card. Given that I had already achieved perfect locality, it didn't seem right for there to still be so much lock contention, so I set out to get to the bottom of it.
I spent days (maybe weeks) just on this one issue. I did gymnastics with tracing tools trying to analyze it. I manually recompiled bpftrace just so I could unsafely trace _raw_spin_lock with a kretprobe. I went to bed thinking about it. I dreamt about it. I would wake up with a bright new idea, but it always turned out to be another dead end. Nevertheless, I kept coming back; it was my white whale. I tried different parameters, different qdiscs, and different kernels. I even tried some hacks that I found for disabling the qdisc altogether. All I got for my trouble was an unreachable instance.
Eventually, with a heavy heart, I decided to throw in the towel. Technically the kernel was behaving as expected. The qdisc related spin locks are a known bottleneck, and kernel developer's attempts to address it so far have been thwarted. Lockless qdisc support was added to kernel 4.16, but it came at the cost of no longer being able to just bypass an empty qdisc entirely (TCQ_F_CAN_BYPASS). This means that for my scenario (uncontended sends/perfect locality), the bottleneck would just get shifted from _raw_spin_lock to __qdisc_run, even though the qdisc was always empty.
I was briefly elated when I found out that support for using TCQ_F_CAN_BYPASS and lockless qdiscs at the same time, had been added to later kernels. Alas, my joy was short-lived. As it turns out, the fix triggered some regressions, and had to be reverted.
# Noqueue to the Rescue
After I had given up the spin lock fight and moved on to other optimizations, I circled back to write down my notes for the Optimizations That Didn't Work section of this blog. I figured I might as well share what I had found, hoping someone else might pick up on something that I had missed. While searching for one of the crazy hacks I had tried (the one that locked up the instance), I came across something that I had overlooked before: the noqueue qdisc.
Documentation on the noqueue qdisc is pretty sparse, but I found some unofficial tc notes that give a reasonable overview. As the name implies, it is a queueing discipline that doesn't actually do any queueing. It is designed to be used with software devices like the loopback interface (localhost) or container based virtual interfaces.
While real devices might need to occasionally stop accepting new packets so they can clear their backlog, software devices basically accept whatever is sent to them; they never apply back-pressure. Back-pressure is what typically causes a packet to get queued by the qdisc, so no back-pressure = no queueing. The rationale for using noqueue with software devices is simple — if the qdisc isn't going to get used anyway, then you might as well avoid the additional overhead altogether. Avoiding overhead sounded like a great idea to me, especially if it would get rid of all those spin locks! The question was, could I make it work with a hardware* device?
The short answer is yes, it is possible to replace pfifo_fast with noqueue as the default qdisc.
sudo sysctl net.core.default_qdisc=noqueue
sudo tc qdisc replace dev eth0 root mq
If you run sudo tc qdisc show dev eth0, after running the commands above, this is what your output would look like on a c5n.xlarge. Keep in mind that this is a multi-queue setup so there is a separate qdisc for each of the network card's transmit queues.
qdisc mq 8001: root
qdisc noqueue 0: parent 8001:4
qdisc noqueue 0: parent 8001:3
qdisc noqueue 0: parent 8001:2
qdisc noqueue 0: parent 8001:1
So now we know that it is possible, but we also know that this isn't really what it was designed to do. I wanted to get a better understanding of whether this was just something you probably shouldn't do or if it was a really, really bad idea.
As a first step I took a look at the code to see what actually happens when you use noqueue. Inside the noqueue_init function the value of the enqueue function is set to NULL. This is essentially how noqueue identifies itself, and it comes into play later when enqueue is tested in __dev_queue_xmit. If enqueue has a value, then the standard (spin lock heavy) qdisc path is taken. If enqueue is NULL the noqueue path is taken, and only a single lock is acquired before dev_hard_start_xmit is called to send the packet to the device.
We should keep in mind that even without the qdisc, the network interface still has its own transmit queue (typically a ring buffer) where outgoing data gets stored while waiting for the network card to pick it up and send it. Simple qdiscs like pfifo_fast serve as an additional buffer that can queue data up if the device is busy. More sophisticated qdiscs like sfq actively schedule packet transmission based on flows, to ensure fairness. Removing the qdisc from the mix means that we must rely on the transmit queue alone. This raises two questions: (1) Are we at risk of filling the transmit queue? (2) What would happen if we did?
I felt pretty confident that I wasn't filling the transmit queue for this specific test. Even though over a million responses are being sent out every second, (a) there are only 256 connections, (b) each response fits in a single packet, and (c) it is a synchronous request/response benchmark. This means that at most, there can only be 256 outgoing packets waiting to be sent at any given time. Furthermore, each of our 4 cpu/queue pairs operates independently, so on a per queue basis there should only ever be a maximum of 64 packets waiting to go. The capacity of the ENA driver's transmit queue is 1024 entries, so we have more than enough headroom.
I wanted to confirm that my expectations matched reality, but the size of the transmit queue is not tracked by the OS or the ENA driver. I created a bpftrace script to record the length of the device's transmit queue whenever ena_com_prepare_tx is called. I ran the bpftrace script with the qdisc set to pfifo_fast, and then noqueue. The results look almost identical, and in both cases, the queue length rarely goes above 64. Here are the results for a single queue:
pfifo_fast
@txq[4593, 1]:
[0, 8) 313971 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[8, 16) 558405 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[16, 24) 516077 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[24, 32) 382012 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[32, 40) 301520 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[40, 48) 281715 |@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[48, 56) 137744 |@@@@@@@@@@@@ |
[56, 64) 9669 | |
[65, ...) 37 | |
noqueue
@txq[4593, 1]:
[0, 8) 338451 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[8, 16) 564032 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[16, 24) 514819 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[24, 32) 380872 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[32, 40) 300524 |@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[40, 48) 281562 |@@@@@@@@@@@@@@@@@@@@@@@@@ |
[48, 56) 141918 |@@@@@@@@@@@@@ |
[56, 64) 11999 |@ |
[65, ...) 112 | |
So we have confirmed that there is no risk of overflowing the transmit queue under our specific benchmark, but I still wanted to know what would happen if it did overflow. According to this document, a networking driver's implementation of the ndo_start_xmit method should return NETDEV_TX_OK on success and NETDEV_TX_BUSY on failure. One of the examples of a failure that would trigger a NETDEV_TX_BUSY response, is the transmit queue being full. When using a normal qdisc like pfifo_fast, this response is handled by requeueing the outgoing data on the qdisc queue. When using noqueue, it triggers an error and the packet gets dropped.
Rather than rely on that theory, I decided to look at the ENA driver source code to see what really happens. What I found was a little surprising. ena_start_xmit() actually handles transmit errors by dropping the packet and returning NETDEV_TX_OK instead of NETDEV_TX_BUSY. If you look at the ena_com_prepare_tx function, there is a check to see if the transmit queue is full. If it is full, a non-zero response code is passed back up the chain, causing the driver to unmap DMA, drop the packet, and return NETDEV_TX_OK. NETDEV_TX_BUSY is never returned in this scenario, which means that neither pfifo_fast, nor noqueue will be called on to handle the back-pressure. It will be up to the higher level protocols, like TCP, to notice that the packet never reached its destination and resend it.
I wanted to run a test to confirm the expected behavior, so I used iPerf to transmit as many packets as possible from the test server to another instance: iperf3 -c 10.XXX.XXX.XXX -P 10 -t 5 -M 88 -p 5200. iPerf sends packets asynchronously, which drastically increases the likelihood of filling the transmit queue. I modified my bpftrace script, and verified that on at least a few occasions, the network card's transmit queue was at full capacity (1024 entries) during the test run. When I ran dmesg to confirm that there were no unexpected errors or warnings from the kernel, I was surprised to find this one: Virtual device eth0 asks to queue packet!.
It turns out that my earlier analysis of the ENA driver code was incomplete. Immediately after a new packet is successfully added to the transmit queue, there is a second test to see if the queue is full at that point, and if it is, the queue is stopped so that the backlog can be cleared. This means that the next outgoing packet might encounter a stopped queue. When there is no qdisc to fall back on, the kernel simply logs a warning and drops the packet, leaving retries up to higher level protocols.
To put things in perspective, I was only able to simulate this "full queue" scenario with a fairly extreme synthetic test, and even then, I would only get about 500-1000 dropped packets in an iPerf test where around 9 million packets were transmitted. Nevertheless, there may still be other corner cases associated with noqueue that I am not aware of, and this is definitely not what it was designed for. Once again, please don't try this in production.
Switching to noqueue gives us a performance boost of just over 2%. Throughput moves from 1.12M req/s to 1.15M req/s.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 213.19us 25.10us 801.00us 77.00us 68.52%
Req/Sec 72.56k 744.45 74.36k 70.37k 65.09%
Latency Distribution
50.00% 212.00us
90.00% 246.00us
99.00% 276.00us
99.99% 338.00us
11551707 requests in 10.00s, 1.57GB read
Requests/sec: 1155162.15
Transfer/sec: 160.84MB
# Flame Graph Analysis
The _raw_spin_lock function at the top of the sendto syscall stack has finally been vanquished. A small _raw_spin_lock call shows up above __dev_queue_xmit, but it weighs in at 0.3% of the flame graph, down from the monstrous 5.4% of its predecessor.

# The White Whale Rises
While I was glad to be rid of the _raw_spin_lock, I still wasn't ready for an all out celebration. Something wasn't quite right. While flame graph percentages don't have a 1-to-1 mapping to performance gains, I expected the throughput improvement to be more than 2% after such a significant change. Further examination of the flame graph revealed an unexpected twist. Out of nowhere, the tcp_event_new_data_sent function grew from 1.1% to 5.1% of the flame graph. Just when I thought I had conquered it, my white whale reemerged in a new form.
After I got past my initial dismay and disbelief, I set about attacking tcp_event_new_data_sent with renewed vigor. I read through the source code but nothing jumped out at me. I analyzed it with bpftrace, confirming that the function was being called the same number of times, and under the same conditions. Attempts at analyzing timing were unsuccessful because the overhead of the analysis was significantly larger than the runtime of the function itself. At one point I wondered if it was just an anomalous artifact of how perf was sampling the data. I was already using the recommended frequency of 99Hz for sampling, but I decided to switch it up just in case. I tried 49Hz, 173Hz, and 263hz. There was no change.
Next I wondered if the issue might be hyper-threading related, so I modified the indirection table to only send data to queue/cpu 0 and queue/cpu 1 (cpu 0 and 1 map to different physical cores on this instance). To my surprise, it worked, tcp_event_new_data_sent shrunk back down to just over 1% of the graph. To my horror, a new beast emerged in its place, release_sock jumped from less than 1% to almost 7% of the flame graph. Ignoring all the warning signs, I pressed on. I decided that I needed to test it with hyper-threading disabled for real, so I used CPU Options to launch an instance with 1 thread per core. I ran the tests again and generated a new flame graph. tcp_event_new_data_sent was back to normal, release_sock was back to normal, but now for some reason tcp_schedule_loss_probe was 11% of the flame graph. What!?!?
This was turning into a bizarre Greek tragedy where I was doomed to an eternity of playing flame graph whack-a-mole against a whale-headed hydra. At that point, I decided that the universe was trying to teach me a lesson. Sometimes you need to stop and appreciate all the things you already have, rather than obsessing over the 5% of things that you don't. So I decided to get back to finishing up this blog post, and I left the whack-a-hydra issue for another day/post.
Do you have any idea what the hell is going on here dear reader? If so, please share with the rest of the class: Hacker News Reddit Direct.
# 9. This Goes to Twelve
I categorize this final trio of optimizations as small improvements that help us squeeze out the last drop of performance even though they are known to negatively impact other common use cases.
# Disabling Generic Receive Offload (GRO)
GRO is a networking feature that is designed to opportunistically merge incoming packets at the kernel level. The reassembled segments are presented to the user-land application as a single block of data. The idea is that reassembly can be done more efficiently in the kernel, thus improving overall performance. Generally this is a setting that you want to leave on, and it is on by default in Amazon Linux 2. However for our benchmark, we already know that all requests and responses easily fit within a single packet, so there is no need for reassembly. Disabling GRO removes the overhead associated with the function used to check if reassembly is needed: dev_gro_receive.
sudo ethtool -K eth0 gro off
# TCP Congestion Control
Linux supports a number of pluggable TCP congestion control algorithms. Each employs a slightly different strategy to optimize the flow of data across the network. At a high level, the algorithms try to slow things down when external network congestion is detected, and speed them back up when the congestion goes away. This is especially important for wireless networks (WiFi, mobile, satellite) where performance is highly variable. It is a lot less useful on a low-latency, congestion-free network like the AWS cluster placement group used in this benchmark.
At first, I didn't give congestion control a second thought, but then an idea occurred to me. Even in an environment where congestion is near zero, the algorithm still has to keep tabs on what is going on. Instead of looking for the best algorithm for adapting to congestion, maybe I should look for the algorithm that has the lowest overhead in a congestion free environment.
Amazon Linux 2 ships with two pre-loaded congestion control options: reno and cubic. Reno (aka NewReno) is built into the kernel; it gets used if no other congestion control module is available. Reno uses one of the simplest approaches, and many of the other algorithms simply offer additional functionality on top of reno. Cubic uses a more sophisticated algorithm, which works better across a wider number of use cases. Cubic is the default congestion control algorithm used on Amazon Linux 2.
If you look at the list of tcp_congestion_ops for reno vs cubic it is pretty clear how much simpler reno is. Switching from cubic to reno results in a small but consistent performance increase.
sudo sysctl net.ipv4.tcp_congestion_control=reno
I tested various other congestion control algorithms as well, including vegas, highspeed and bbr. This required me to manually load the relevant kernel modules first, e.g. modprobe tcp_bbr. None of them were faster than reno for this benchmark.
# Static Interrupt Moderation
The adaptive-rx interrupt moderation feature is extremely powerful and versatile, but it adds a tiny bit of overhead/variability under heavy load, and it seems to max out at 256 usecs. Disabling adaptive-rx and using a relatively high static value results in slightly improved (and much more consistent) throughput and latency values. I arrived at 300 usecs as the optimal value (for this specific test) through trial and error.
Hard-coding rx-usecs will have a pretty big negative impact on response times for lighter workloads like a ping test. It also has a negative impact if you disable BPF or busy polling; something to be aware of if you decide to play around with this benchmark. Note that this optimization is not included in the CloudFormation template.
sudo ethtool -C eth0 adaptive-rx off
sudo ethtool -C eth0 rx-usecs 300
sudo ethtool -C eth0 tx-usecs 300
These final optimizations give us a performance boost of over 4%. Throughput moves from 1.15M req/s to 1.2M req/s.
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 204.24us 23.94us 626.00us 70.00us 68.70%
Req/Sec 75.56k 587.59 77.05k 73.92k 66.22%
Latency Distribution
50.00% 203.00us
90.00% 236.00us
99.00% 265.00us
99.99% 317.00us
12031718 requests in 10.00s, 1.64GB read
Requests/sec: 1203164.22
Transfer/sec: 167.52MB
# Flame Graph Analysis
No huge changes here. dev_gro_receive drops from 1.4% to 0.1% of the flame graph. bictcp_acked (one of the functions used by the cubic algorithm) was previously 0.3% but now it has disappeared from the flamegraph entirely.

With that, dear friends, we have arrived at our final destination. It was a long, twisted, and oftentimes frustrating journey, but in the end it was worth it. I learned a tremendous amount along the way and I am pretty happy with the final result. A 436% increase in requests per second along with a 79% reduction in p99 latency is no mean feat, especially for a server that was already pretty fast to begin with.
Initial Results
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 1.14ms 58.95us 1.45ms 0.96ms 61.61%
Req/Sec 14.09k 123.75 14.46k 13.81k 66.35%
Latency Distribution
50.00% 1.14ms
90.00% 1.21ms
99.00% 1.26ms
99.99% 1.32ms
2243551 requests in 10.00s, 331.64MB read
Requests/sec: 224353.73
Transfer/sec: 33.16MB
Final Results
Running 10s test @ http://server.tfb:8080/json
16 threads and 256 connections
Thread Stats Avg Stdev Max Min +/- Stdev
Latency 204.24us 23.94us 626.00us 70.00us 68.70%
Req/Sec 75.56k 587.59 77.05k 73.92k 66.22%
Latency Distribution
50.00% 203.00us
90.00% 236.00us
99.00% 265.00us
99.99% 317.00us
12031718 requests in 10.00s, 1.64GB read
Requests/sec: 1203164.22
Transfer/sec: 167.52MB
# libreactor vs the world
The bar charts below show a comparison of the initial (round 18) and final (round 20) libreactor implementations vs some of the most popular (or performant) implementations of the Techempower JSON benchmark as at round 20.
The first chart shows the results from running all 11 implementations on a c5n.xlarge using the stock Amazon Linux 2 AMI without any OS/Networking optimizations. You can see that the application level optimizations added between round 18 and round 20 are just enough to take libreactor to the front of the pack.
The second chart shows the rising tide of OS/Networking optimizations lifting all ships. It also shows how well those optimizations combine with libreactor's round 20 optimizations, propelling libreactor (r20) even further ahead of the pack. The lower segment of each bar represents the performance achieved before the OS/Networking optimizations were applied.
Note that these results won't line up with the official Techempower round 20 JSON results because of a known issue. In their test setup the client instance is the same size as the server, so for the JSON test it becomes the bottleneck. The top 10 JSON implementations are all effectively capped at around 1.6M req/s. As a rough proxy for expected performance you can look at the visualization of the server CPU usage for round 20. libreactor's CPU usage was only 47%, while ulib-json_fit used 75% and pico.v used 90%.
Techempower is exploring options to address this limitation in their environment by also using their database server to generate load during JSON tests. Additionally, Fredrik Widlund recently released a wrk-like benchmarking tool called pounce, that uses the libreactor framework. My rough initial tests have shown it to be 20-30% faster than wrk, so it may also come in handy to the team over at Techempower.
# Advice from a weary traveler
This adventure was fueled by my curiosity, willingness to learn, and relentless persistence; but I was only able to achieve success by repeatedly putting assumptions to the side, and taking advantage of the tools available to measure, analyze, and understand my application. I consistently profiled my workload using FlameGraph to identify potential optimizations and confirm their effectiveness. Whenever things didn't seem to quite add up, I used bpftrace to test different hypotheses, and validate expectations.
For those who are reading this post in search of performance tuning ideas, I encourage you to take the same approach. Before you even think about disabling syscall auditing or seccomp, the first thing you should do is generate a flame graph, and see if those functions are even visible for your workload. They probably aren't. However, there is always the possibility that the flame graph will reveal some other bottleneck, or give you some deeper insight into what is going on with your OS/application.
# What's next?
As happy as I am with the final result, I am also curious to know if there is anything that I missed. Please let me know if you are aware of any relevant optimizations that I didn't cover. But before you run to Hacker News or Reddit to, please read through my list of things that I already tried that didn't work.
Looking to the future, I already have plans to do an ARM vs Intel showdown at some point, pitting the Graviton2 based c6gn against the c5n (and the new m5zn). I will probably get to that one as soon as this networking issue with the c6gn is resolved. Investigating io_uring as an alternative to epoll is also on my radar. Do you have a suggestion for what else I should tackle? Drop me a line.
# What a time to be alive
As I mentioned before, 15 years ago I couldn't even imagine taking on a project like this "just for fun". What's more, even if I happened to have access to the necessary hardware, it would have been much more difficult for others to replicate exactly what I did. Thanks to the power of cloud computing, all of that has changed.
As fantastical as these results may seem, they aren't just some theoretical ideas being tested on exotic, inaccessible hardware. Almost anyone with a little time and money can use this template, and try it out for themselves on the same hardware. If you already have experience with AWS/CloudFormation, you can probably do it in less than an hour, for less than a dollar. The opportunities for exploration and experimentation that the cloud model enables are truly game changing.
# Special Thanks
I want to share my appreciation for the numerous blog posts, papers, presentations and tools that I learned from along the way. A more complete reference section is below, but I want to highlight a few that stand out the most:
- Special thanks to the folks at packagecloud.io whose extremely detailed breakdown of the Linux networking stack was immensely helpful. The first time I skimmed it, it was mostly Greek to me. I had to read, and re-read it bit by bit, before it really clicked. Even though it was originally written for the 3.13 kernel it is still very useful today. It also focuses on UDP instead of TCP, but there is a lot of overlap.
- I stumbled across Toshiaki Makita's awesome Boost UDP Transaction Performance presentation mid-way through the process. It not only served as a practical and effective demonstration of using flame graphs to search for performance bottlenecks, but it also helped re-energize my drive to hit the 1M mark at a point when the prospects were looking dim.
- Brendan Gregg's Flamegraph tool and his book BPF Performance Tools were instrumental. I used FlameGraph and bcc/bpftrace throughout the process. Check out Brendan's newly released Systems Performance: Enterprise and the Cloud, 2nd Edition if you are really interested in this stuff.
- Thanks to Fredrik Widlund and Will Glozer for creating libreactor and wrk.
- Thanks to the Linux kernel developers whose work is the foundation on which this is all built. If someone had told me a year ago that I would end up spending hours reading through the kernel source code, I honestly wouldn't have believed them.
Last, but certainly not least, extra special thanks to my reviewers: Kenia, Nesta, Andre, Crafton, Kaiton, Dionne, Kwaku, and Monique.
# Optimizations That Didn't Work
Here is an incomplete listing of the things I tried that didn't work out.
-
libreactor
- Running as a standalone binary without docker
- Using
writevinstead ofsend(slower) - Larger value for maxevents with epoll_wait
- Different gcc versions
- Various march/mtune options
- Investigate other gcc flags
-
Kernel
- Upgrade to 4.19 (Amazon Linux 2)
- Upgrade to 5.4 (Amazon Linux 2 and Ubuntu 20.04)
- SCHED_FIFO and SCHED_RR schedulers
- kernel.sched_min_granularity_ns
- kernel.sched_wakeup_granularity_ns
- transparent_hugepages=never
- skew_tick=1
- clocksource=tsc
-
Networking
- ENA Driver
- Offload features (segmentation, scatter-gather, rx/tx checksum)
- Recompile ena with -O3
- ENA params
- ena.rx_queue_size
- ena.force_large_llq_header
- Disable IPv6: ipv6.disable=1
- Disable VLAN: sudo modprobe -rv 8021q
- Disable source validation
- net.ipv4.conf.all.rp_filter=0
- net.ipv4.conf.eth0.rp_filter=0
- net.ipv4.conf.all.accept_local=1 (made perf worse)
- net.ipv4.tcp_sack=0
- net.ipv4.tcp_dsack=0
- net.ipv4.tcp_mem/tcp_wmem/tcp_rmem (the defaults are plenty)
- net.core.netdev_budget
- net.core.dev_weight (Not relevant unless you are using RPS)
- net.core.netdev_max_backlog (Not relevant unless you are using RPS)
- net.ipv4.tcp_slow_start_after_idle=0 (Not relevant)
- net.ipv4.tcp_moderate_rcvbuf=0
- net.ipv4.tcp_timestamps=0
- net.ipv4.tcp_low_latency=1 (legacy option)
- SO_PRIORITY
- TCP_NODELAY
- ENA Driver
# Full Benchmark Setup
# Additional Details
The details below are in addition to what was covered in the Basic Benchmark Setup section.
# Software
-
Operating System (client and server):
- EC2 AMI: amzn2-ami-hvm-2.0.20210126.0-x86_64-gp2
- Linux sysctls:
- vm.swappiness=0
- vm.dirty_ratio=80
- net.core.somaxconn=2048
- net.ipv4.tcp_max_syn_backlog=10000
- amazon-ssm-agent was disabled to avoid potential interference
# Network
Hardware/Driver: Both the client and the server were connected to the network via Amazon's Nitro Card for VPC, and running version 2.4.0 of the Elastic Network Adapter (ENA) driver. The network interface supports multiple network queues (1 per vCPU), Receive side scaling (RSS), and a working mode called Low-latency Queue (LLQ).
IP Addresses: The instances were only issued IPv4 addresses. No IPv6 addresses were issued.
Throughput Limits: AWS only provides guaranteed bandwidth for instance sizes greater than 4xlarge. The c5n.xlarge is capable of burst capacity up to 25 Gbps and 1.8M pps for short periods of time, but it has much lower baseline limits. These test runs were deliberately kept short to avoid exceeding burst allowances. If you are running the latest version of the ENA driver, you should be able to check whether or not you have exceeded the allowance using recently added metrics that can be queried using ethtool, e.g.
ethtool -S eth0 grep exceeded.
# Flame Graph Generation
The flame graphs in this post were generated by manually starting perf record while the benchmark was running. To better highlight the details of the flame graphs and provide visual consistency across the board, a slightly different version of libreactor was used when creating flame graphs vs doing "real" benchmarking runs. The flame graph friendly versions of libreactor were built with the -fno-inline, -fomit-frame-pointer, and -flto GCC options at every stage. The following commands were used to generate the flame graphs (along with this custom palette.map):
sudo perf record -F 99 --call-graph dwarf --pid $(pgrep -d ',' 'libreactor')
sudo perf script ./stackcollapse-perf.pl --kernel ./flamegraph.pl --width 1600 --bgcolors grey --cp > output.svg
# Advanced Setup
I used the setup described so far while identifying and evaluating the optimizations covered in this post, but for the final test run I wanted to go the extra mile to reduce any variability that might negatively influence the results. My primary goal was to minimize inconsistencies at the platform/OS/network level, so as to ensure that the changes being measured were the result of the optimizations applied at each stage, not some external factor.
You can probably still hit 1.2M req/s without these steps but you will see more variability in throughput and a lot more variability in p99 and p99.99 latency.
# Avoiding Noisy Neighbors and Intel Turbo Boost Variability
I did the final benchmark run on a c5n.9xlarge that was restricted to 4 vCPUS using the EC2 CPU Options feature. This meant two things:
- No other VM was running on the same NUMA node as the test server.
- Intel Turbo Boost was always on.
In my testing, when Turbo Boost was on, it increased stress-ng CPU performance (stress-ng --matrix 0 --metrics-brief -t 7) by about 2% compared to when it wasn't. Ensuring that it was always on prevents an unexpected 2% shift that could happen if my VM neighbors were unusually quiet for one particular run.
I had tried running the benchmark with the client and server on the same dedicated host to avoid noisy neighbors and network latency variance, but I ran into this issue. As it turns out, performance degrades for this test when running on a dedicated host.
# Confirming Low Latency
The average latency between two servers in a cluster placement group is generally in the 40μs - 60μs range depending on how you measure it
- ICMP (
ping -U): 35μs - 60μs - TCP (
sockperf ping-pong): 40μs - 65μs
Nevertheless, you can still get an outlier from time to time, so I stopped/started my instances until I had better than average client-server latency. The results for the instances used in this test run were definitely above average, but you should be good with anything in the 50μs range:
Command: sudo ping -U -q -i 0 -s 18 -w 10 10.XXX.XXX.XXX
Result: 39μs
249138 packets transmitted, 249137 received, 0% packet loss, time 10000ms
rtt min/avg/max/mdev = 0.035/0.039/0.155/0.008 ms, ipg/ewma 0.040/0.040 ms
Command: sockperf ping-pong --tcp --full-rtt -m 14 -i 10.XXX.XXX.XXX -t 10
Result: 44μs
sockperf: Summary: Round trip is 44.804 usec
sockperf: Total 212861 observations; each percentile contains 2128.61 observations
sockperf: ---> observation = 143.388
sockperf: ---> percentile 99.999 = 67.481
sockperf: ---> percentile 99.990 = 65.303
sockperf: ---> percentile 99.900 = 60.829
sockperf: ---> percentile 99.000 = 50.901
sockperf: ---> percentile 90.000 = 46.082
sockperf: ---> percentile 75.000 = 45.163
sockperf: ---> percentile 50.000 = 44.556
sockperf: ---> percentile 25.000 = 44.014
sockperf: ---> observation = 38.849
# Stopping Non-critical Services
After boot up, I stopped all non-critical services on the instance to prevent them muddying up my latency numbers. You may be surprised to learn this included stopping dockerd and containerd. The libreactor processes keep running even after dockerd/containerd is stopped courtesy of Docker's live restore feature. A timely reminder that a "container" is really just one or more Linux processes running in a custom namespace.
Here are the commands I used to stop non-critical services:
sudo systemctl stop containerd
sudo systemctl stop docker
sudo systemctl stop rsyslog
sudo systemctl stop postfix
sudo systemctl stop crond
sudo systemctl stop chronyd
sudo systemctl stop libstoragemgmt
sudo systemctl stop systemd-journald.socket
sudo systemctl stop systemd-journald
sudo systemctl stop rpcbind.socket
sudo systemctl stop rpcbind
sudo service auditd stop
Disabling these services can have a number of unexpected side effects, so I didn't include these commands in my CloudFormation template. It should also go without saying that I wasn't running any interactive programs (e.g. htop) while collecting benchmark results.
# ARP Record Caching
I changed these sysctls to allow ARP records to be cached and reduce the frequency of cache refreshes.
sudo sysctl -w net.ipv4.neigh.default.gc_thresh1=128
sudo sysctl -w net.ipv4.neigh.default.gc_interval=300
sudo sysctl -w net.ipv4.neigh.eth0.gc_stale_time=300
This was deliberately left out of the CloudFormation template as well.
# EC2 X-factor?
Even after taking all the steps above, I still regularly saw a 5-10% variance in performance across two seemingly identical EC2 server instances. I tested and ruled out the following things as causes:
- TCP latency differences (sockperf)
- CPU performance differences (stress-ng)
- Noisy neighbors/CPU steal (9xlarge + sar)
- Intel Turbo Boost (turbostat)
- CPU model (lscpu)
There still seems to be some other underlying hardware or firmware difference that I was unable to detect. If anyone has any ideas about this, please let me know: Hacker News Reddit Direct.
To work around this variance, I tried to use the same instance consistently across all benchmark runs. If I had to redo a test, I painstakingly stopped/started my server instance until I got an instance that matched the established performance of previous runs.
# CloudFormation Template
This AWS CloudFormation template will create a ready-made benchmark environment for you with all the optimizations applied except for static interrupt moderation. The advanced section below has the commands needed to turn static interrupt moderation on; but remember, you will need to run your ping tests first, otherwise they will be distorted.
The only template parameters that you need to provide are:
- An EC2 instance key pair.
- A VPC Subnet (any subnet in the default VPC is fine).
- A VPC Security Group (the default security group for the default VPC is fine).
If you are new to AWS, always, always, always set up a billing alarm for your account before you start playing around.
Don't forget to stop the instances when you are not using them; and remember to delete the CloudFormation stack when you are done. The default configuration will run you about $1 per hour in us-east-2. That is "cheap" if you only run it for an hour, but very expensive if you forget and leave it running for a month.
Keep in mind that stopped instances still incur EBS charges. Around $0.05 per day with the default configuration.
# Things to Note
The instances are configured to automatically build twrk and libreactor for you the first time they start up. They will also automatically reboot to apply the kernel parameter changes. You might want to wait 3-4 minutes before you try to login for the very first time.
The CloudFormation template will automatically use the latest available version of Amazon Linux 2. As of right now that is
amzn2-ami-hvm-2.0.20210427.0-x86_64-gp2, but as soon as a newer version is released, that version will become the default. Newer releases may negatively (or positively) impact the benchmark.If you run the benchmark too frequently, or for too long, you might exceed the instance's burst allowances. You can use this command to check:
ethtool -S eth0 grep exceeded.You can expect your results to range between 1.1M req/s and 1.2M req/s as a result of variances in performance between EC2 instances.
# Benchmark Steps
Add a rule to the security group to allow SSH connections from your IP (only).
SSH to the client and server using their public IP addresses.
-
Ping the server's private IP from the client to confirm that latency is within the expected range (40μs - 60μs).
sudo ping -U -q -i 0 -s 18 -w 10 172.31.XX.XX -
Run the libreactor docker container on the server.
docker run -d --rm --security-opt seccomp=unconfined --network host --init libreactor -
Run twrk on the client, using the server's private IP in the url.
twrk -t 16 -c 256 -D 2 -d 10 --latency --pin-cpus "http://172.31.XX.XX:8080/json" -H 'Host: server.tfb' -H 'Accept: application/json,text/html;q=0.9,application/xhtml+xml;q=0.9,application/xml;q=0.8,*/*;q=0.7' -H 'Connection: keep-alive'
Here be dragons. Make sure you read through the Advanced Setup section, and understand the implications before running any of these commands.
-
Enable static interrupt moderation.
sudo ethtool -C eth0 adaptive-rx off sudo ethtool -C eth0 rx-usecs 300 sudo ethtool -C eth0 tx-usecs 300 -
Stop non-critical services.
sudo systemctl stop containerd sudo systemctl stop docker sudo systemctl stop rsyslog sudo systemctl stop postfix sudo systemctl stop crond sudo systemctl stop chronyd sudo systemctl stop libstoragemgmt sudo systemctl stop systemd-journald.socket sudo systemctl stop systemd-journald sudo systemctl stop rpcbind.socket sudo systemctl stop rpcbind sudo service auditd stop -
Enable ARP record caching.
sudo sysctl -w net.ipv4.neigh.default.gc_thresh1=128 sudo sysctl -w net.ipv4.neigh.default.gc_interval=300 sudo sysctl -w net.ipv4.neigh.eth0.gc_stale_time=300
# Linux Kernel Networking Resources
- Scaling in the Linux Networking Stack (RSS/RPS/RFS/XPS)
- Linux kernel SMP IRQ affinity
- Linux Network Scaling: Receiving Packets
- Linux Network Receive Stack: Monitoring and Tuning Deep Dive
- Queueing in the Linux Network Stack
- packagecloud's in depth kernel networking series
- Busy Polling
- Toshiaki Makita's LinuxCon presentation: Boost UDP Transaction Performance
- Perfect locality and three epic SystemTap scripts
- Tuned: Daemon for monitoring and adaptive tuning of system devices
- Beej's Guide to Network Programming
# Tools and Software
- Linux perf
- BPF Compiler Collection (BCC)
- bpftrace
- Flame Graphs
- sockperf
- wrk: an HTTP benchmarking tool
- libreactor: a modular event driven application framework
- Linux kernel driver for Elastic Network Adapter (ENA) family
# Speculative Execution Vulnerabilities
- List of kernel mitigations and how to control/disable them
- Full list of all speculative execution vulnerabilities, many of which have no available fix
- AWS Bulletin regarding Spectre/Meltdown class vulnerabilities
- AWS re:Invent 2019: Speculation & leakage: Timing side channels & multi-tenant computing (SEC355)
[ comments ]